SkyHive is an end-to-end reskilling platform that automates expertise evaluation, identifies future expertise wants, and fills ability gaps by means of focused studying suggestions and job alternatives. We work with leaders within the house together with Accenture and Workday, and have been acknowledged as a cool vendor in human capital administration by Gartner.
We’ve already constructed a Labor Market Intelligence database that shops:
- Profiles of 800 million (anonymized) employees and 40 million firms
- 1.6 billion job descriptions from 150 international locations
- 3 trillion distinctive ability mixtures required for present and future jobs
Our database ingests 16 TB of knowledge each day from job postings scraped by our internet crawlers to paid streaming knowledge feeds. And we’ve performed loads of advanced analytics and machine studying to glean insights into world job traits at present and tomorrow.
Due to our ahead-of-the-curve know-how, good word-of-mouth and companions like Accenture, we’re rising quick, including 2-4 company prospects each day.
Pushed by Knowledge and Analytics
Like Uber, Airbnb, Netflix, and others, we’re disrupting an business – the worldwide HR/HCM business, on this case – with data-driven providers that embrace:
- SkyHive Ability Passport – a web-based service educating employees on the job expertise they should construct their careers, and assets on the right way to get them.
- SkyHive Enterprise – a paid dashboard (under) for executives and HR to investigate and drill into knowledge on a) their staff’ aggregated job expertise, b) what expertise firms want to reach the longer term; and c) the abilities gaps.
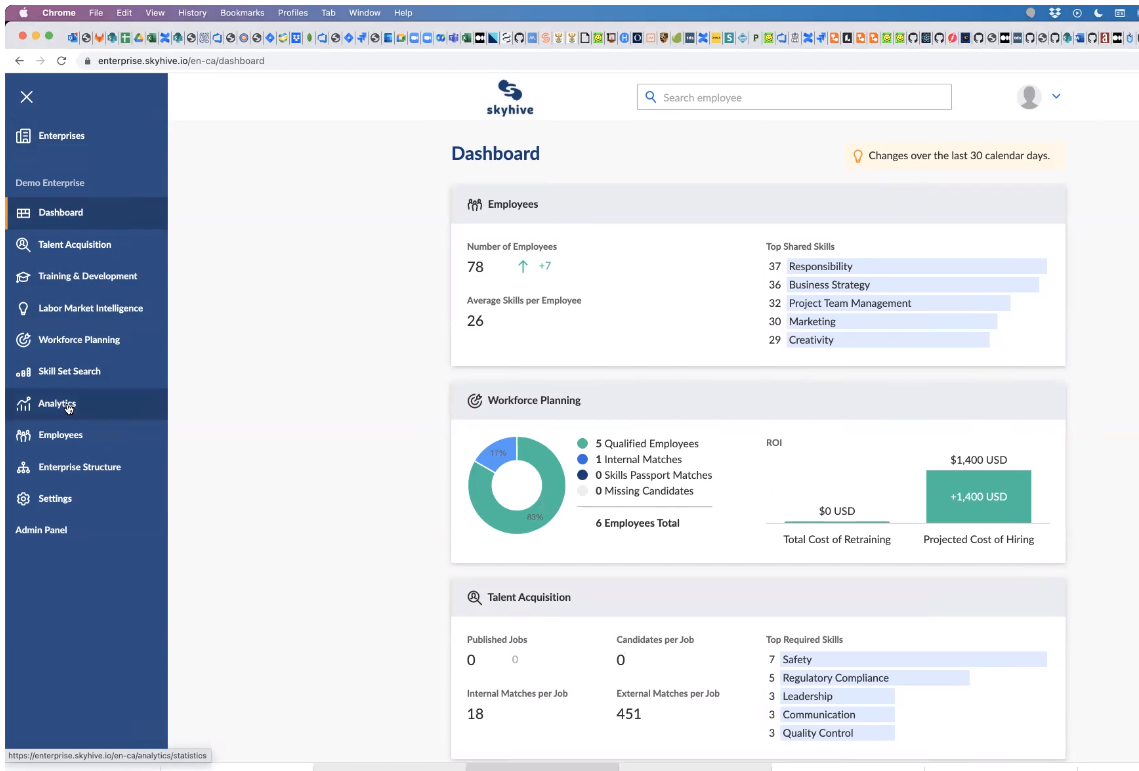
- Platform-as-a-Service by way of APIs – a paid service permitting companies to faucet into deeper insights, equivalent to comparisons with opponents, and recruiting suggestions to fill expertise gaps.
Challenges with MongoDB for Analytical Queries
16 TB of uncooked textual content knowledge from our internet crawlers and different knowledge feeds is dumped each day into our S3 knowledge lake. That knowledge was processed after which loaded into our analytics and serving database, MongoDB.

MongoDB question efficiency was too sluggish to assist advanced analytics involving knowledge throughout jobs, resumes, programs and completely different geographics, particularly when question patterns weren’t outlined forward of time. This made multidimensional queries and joins sluggish and expensive, making it inconceivable to supply the interactive efficiency our customers required.
For instance, I had one giant pharmaceutical buyer ask if it will be potential to search out all the knowledge scientists on the planet with a scientific trials background and three+ years of pharmaceutical expertise. It could have been an extremely costly operation, however after all the shopper was on the lookout for speedy outcomes.
When the shopper requested if we may increase the search to non-English talking international locations, I needed to clarify it was past the product’s present capabilities, as we had issues normalizing knowledge throughout completely different languages with MongoDB.
There have been additionally limitations on payload sizes in MongoDB, in addition to different unusual hardcoded quirks. As an example, we couldn’t question Nice Britain as a rustic.
All in all, we had vital challenges with question latency and getting our knowledge into MongoDB, and we knew we wanted to maneuver to one thing else.
Actual-Time Knowledge Stack with Databricks and Rockset
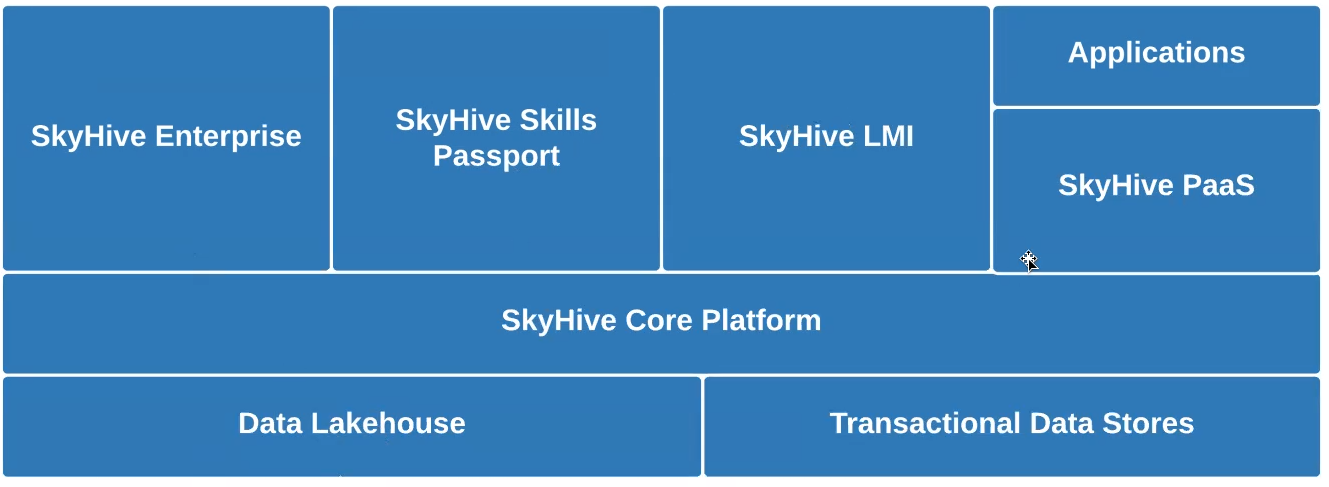
We would have liked a storage layer able to large-scale ML processing for terabytes of latest knowledge per day. We in contrast Snowflake and Databricks, selecting the latter due to Databrick’s compatibility with extra tooling choices and assist for open knowledge codecs. Utilizing Databricks, we’ve deployed (under) a lakehouse structure, storing and processing our knowledge by means of three progressive Delta Lake levels. Crawled and different uncooked knowledge lands in our Bronze layer and subsequently goes by means of Spark ETL and ML pipelines that refine and enrich the info for the Silver layer. We then create coarse-grained aggregations throughout a number of dimensions, equivalent to geographical location, job operate, and time, which are saved within the Gold layer.

We’ve SLAs on question latency within the low tons of of milliseconds, whilst customers make advanced, multi-faceted queries. Spark was not constructed for that – such queries are handled as knowledge jobs that might take tens of seconds. We would have liked a real-time analytics engine, one which creates an uber-index of our knowledge as a way to ship multidimensional analytics in a heartbeat.
We selected Rockset to be our new user-facing serving database. Rockset repeatedly synchronizes with the Gold layer knowledge and immediately builds an index of that knowledge. Taking the coarse-grained aggregations within the Gold layer, Rockset queries and joins throughout a number of dimensions and performs the finer-grained aggregations required to serve person queries. That allows us to serve: 1) pre-defined Question Lambdas sending common knowledge feeds to prospects; 2) advert hoc free-text searches equivalent to “What are all the distant jobs in the US?”
Sub-Second Analytics and Sooner Iterations
After a number of months of growth and testing, we switched our Labor Market Intelligence database from MongoDB to Rockset and Databricks. With Databricks, we’ve improved our potential to deal with big datasets in addition to effectively run our ML fashions and different non-time-sensitive processing. In the meantime, Rockset permits us to assist advanced queries on large-scale knowledge and return solutions to customers in milliseconds with little compute value.
As an example, our prospects can seek for the highest 20 expertise in any nation on the planet and get outcomes again in close to actual time. We will additionally assist a a lot larger quantity of buyer queries, as Rockset alone can deal with tens of millions of queries a day, no matter question complexity, the variety of concurrent queries, or sudden scale-ups elsewhere within the system (equivalent to from bursty incoming knowledge feeds).
We at the moment are simply hitting all of our buyer SLAs, together with our sub-300 millisecond question time ensures. We will present the real-time solutions that our prospects want and our opponents can not match. And with Rockset’s SQL-to-REST API assist, presenting question outcomes to functions is simple.
Rockset additionally hastens growth time, boosting each our inner operations and exterior gross sales. Beforehand, it took us three to 9 months to construct a proof of idea for patrons. With Rockset options equivalent to its SQL-to-REST-using-Question Lambdas, we will now deploy dashboards personalized to the potential buyer hours after a gross sales demo.
We name this “product day zero.” We don’t need to promote to our prospects anymore, we simply ask them to go and check out us out. They’ll uncover they’ll work together with our knowledge with no noticeable delay. Rockset’s low ops, serverless cloud supply additionally makes it straightforward for our builders to deploy new providers to new customers and buyer prospects.

We’re planning to additional streamline our knowledge structure (above) whereas increasing our use of Rockset into a few different areas:
- geospatial queries, in order that customers can search by zooming out and in of a map;
- serving knowledge to our ML fashions.
These initiatives would seemingly happen over the subsequent 12 months. With Databricks and Rockset, we’ve already reworked and constructed out a good looking stack. However there may be nonetheless way more room to develop.