“In a earlier weblog submit on this sequence, we talked about utilizing chaos engineering and fault injection strategies to validate the resilience of your cloud purposes. Chaos testing helps enhance confidence in your purposes by discovering and fixing resiliency points earlier than they have an effect on clients and streamlining your incident response by decreasing or avoiding downtime, information loss, and buyer dissatisfaction. To allow this, we launched a brand new platform for resilience validation by way of chaos testing—Azure Chaos Studio. As of November 1, 2023, Chaos Studio is now typically accessible and able to use in 17 manufacturing areas. I’ve requested Chris Ashton, Principal Program Supervisor from the Chaos Studio Engineering crew to share extra on when it’s greatest to implement the important thing options that help reliability of your purposes.”—Mark Russinovich, CTO, Azure.
Design and implement, validate and measure
Design for failure. Step one in constructing a resilient software is to start out with the Microsoft Azure Properly-Architected Framework and leverage the steering to architect an software that’s designed to deal with failure. Construct resilience into your software by way of using availability zones, area pairing, backups, and different really helpful strategies. Incorporate Azure Monitor to allow statement of your software’s well being. Set up well being measures to your software and monitor key metrics like Service Stage Goal (SLO), Restoration Time Goal (RTO), Restoration Level Goal (RPO), and different metrics which might be significant to your software and enterprise. Earlier than deploying your software to manufacturing for buyer use, nevertheless, you wish to confirm that it really handles disruptive situations as anticipated and that it’s really resilient. That is the place chaos engineering and Microsoft Azure Chaos Studio are available in.

Azure Chaos Studio
Enhance software resilience with chaos engineering and testing
Chaos engineering is the observe of injecting faults into an software to validate its resilience to the real-world outage eventualities it can encounter in manufacturing. Chaos engineering is greater than testing—it means that you can validate structure selections, configuration settings, code high quality, and monitoring elements, in addition to your incident response course of. Chaos engineering is greatest utilized through the use of the scientific methodology:
- Kind a speculation
- Carry out fault injection experiments to validate it
- Analyze the outcomes
- Make adjustments
- Repeat
Chaos validation could be added to automated launch pipeline validation or could be carried out manually as a drill occasion, usually referred to as a “sport day.” Including chaos to your steady integration (CI), steady supply (CD), and steady validation (CV) pipeline means that you can gate code circulate based mostly on the end result, offers confidence within the capacity to deal with nominal situations, and means that you can frequently consider the resilience of latest code in an ever-changing cloud atmosphere. Chaos will also be mixed with load, end-to-end, and different take a look at instances to reinforce their protection. Chaos drills and sport days can be utilized much less steadily to validate extra uncommon and excessive outage eventualities and to show catastrophe restoration (DR) capabilities.
Chaos testing is utilized in many organizations in a wide range of methods. Some groups carry out month-to-month drill occasions, others have added automated Chaos to launch pipeline automation, and a few do each. Often, the aim of drill occasions is to validate resilience to a particular real-world state of affairs, reminiscent of AAD or Area Identify System (DNS) happening, or to show Enterprise Continuity and Catastrophe Restoration (BCDR) compliance. Features of drills could be automated, however they require folks to plan, orchestrate, monitor, and analyze the resilience of the system below take a look at.
In CI/CD launch pipeline automation, the objective is to completely automate resilience validation and catch defects early. Primarily based on the outcomes, many groups block manufacturing deployment if their chaos validation fails. Some groups have chaos testing success metrics they monitor for “resiliency regressions caught” and “incidents prevented.” On the Chaos Studio crew, we carry out scenario-focused drills towards the totally different microservices that make up the product. We additionally use chaos testing as a method to prepare new on-call engineers. In doing so, engineers can see the influence of an actual challenge and be taught the steps of monitoring, analyzing, and deploying a repair in a secure atmosphere with out the stress to repair a customer-impacting challenge throughout an precise outage. When an actual challenge does come up, they’re higher geared up to take care of it with confidence.
Inside Microsoft Azure Chaos Studio
Chaos Studio is Microsoft’s resolution to enable you measure, perceive, enhance, and preserve the resilience of your software by way of hypothesis-driven chaos experiments. Chaos Studio is deeply built-in with Azure to offer secure chaos validation at scale.
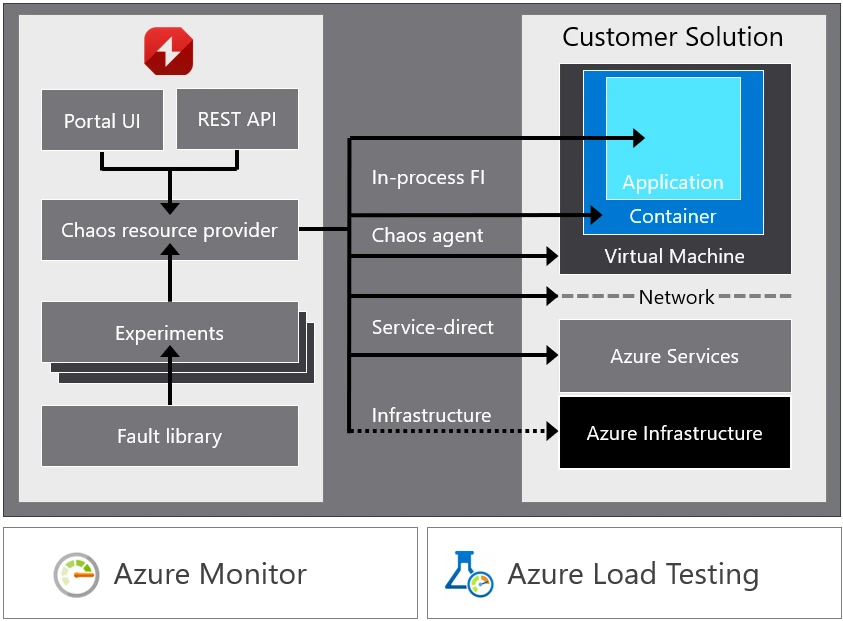
Chaos Studio supplies:
- A completely managed service to validate Microsoft Azure software and repair resilience.
- Deep Azure integration, together with an Azure Portal person interface, Azure Useful resource Supervisor compliant REST APIs, and integration with Azure Monitor and Azure Load Testing—all of which allow handbook and automatic creation, provisioning, and execution of fault injection experiments.
- An increasing library of frequent useful resource stress and dependency disruption faults and actions that work together with your Azure infrastructure as a service (IaaS) and Azure platform as a service (PaaS) assets.
- Superior workflow orchestration of parallel and sequential fault actions that permits simulation of real-world disruption and outage eventualities.
- Safeguards that reduce the influence radius and allow management of who performs experiments and in what environments.
A chaos experiment is the place all of the motion occurs. There are a number of key elements of a chaos experiment:
- Your software to be validated. This have to be deployed to a take a look at atmosphere, ideally one that’s reflective of your manufacturing atmosphere. Whereas this could possibly be your manufacturing atmosphere, we suggest testing in an remoted atmosphere, at the least at first, to attenuate potential influence to your clients.
- Experiment targets are the Azure assets provisioned and enabled to be used in chaos experiments which could have faults utilized to them.
- Fault actions are the orchestrated disruptions and actions to the applying and its dependencies and are supplied by Chaos Studio. These could be easy useful resource stress faults like CPU, reminiscence, and disk stress, community delays and blocks, or extra harmful actions like killing a course of, shutting down a digital machine (VM), inflicting an Azure Cosmos DB failover, and different actions like a easy delay or beginning an Azure Load Testing load take a look at case.
- Site visitors is an artificial workload or precise buyer site visitors towards the applying to create production-like buyer utilization. Customers might add artificial load instantly in chaos experiments by leveraging Azure Load Testing fault actions.
- Monitoring is used to watch software well being and habits throughout an experiment.
Actual world eventualities could be validated by constructing experiments that leverage a number of faults without delay. Systematic disruption of particular person dependencies like Microsoft Azure Storage, SQL Server, or Azure Cache for Redis may be very helpful, however actual worth comes when validating real-world outage eventualities like an availability zone outage from an influence outage in a datacenter, crush load resulting from a vacation gross sales occasion, tax day, or DNS happening. You possibly can construct experiments to regression take a look at the basis reason for your final main outage.
Chaos Studio greatest practices and ideas
Chaos Studio means that you can monitor and enhance your purposes by offering tight integration with Azure Monitor and your CI/CD pipelines. By integrating with Azure Monitor, you may have a view into the lifecycle of your experiments together with in-depth information on timing and the faults and assets focused by the experiment. This information can stay side-by-side together with your current Azure Monitor dashboards or added to your exterior monitoring dashboards. By incorporating Chaos Studio into your CI/CD pipeline, it means that you can repeatedly validate the resilience of your system by operating chaos experiments as a part of your construct and deployment course of.
That can assist you get began together with your chaos journey, listed below are just a few ideas and practices which have helped others:
- Pilot: Don’t simply bounce in and begin injecting faults. Whereas that may be enjoyable, take a methodical method and arrange a throw-away take a look at atmosphere to observe onboarding targets, creating experiments, establishing monitoring, and operating the experiments to determine how totally different faults work and the way they influence totally different assets. When you’re used to the product, spend time to find out easy methods to safely deploy chaos right into a broader, production-like take a look at atmosphere.
- Hypotheses: Formulate resilience hypotheses based mostly in your software structure and take into consideration the experiments you wish to carry out, the stuff you wish to validate, and the eventualities try to be resilient to.
- Drill: Decide a speculation and plan for a drill occasion. Line up experiments associated to the hypotheses, guarantee monitoring is in place, notify different customers of the take a look at atmosphere, do a pre-drill well being examine, after which run your experiment to inject faults. Through the drill, monitor your software well being. After, conduct a retrospective to investigate outcomes and evaluate towards hypotheses.
- Automation: To additional enhance resiliency in your software program improvement lifecycle, you possibly can gate your manufacturing code circulate based mostly on the outcomes of automated Chaos validation.
This could offer you a primary understanding of how chaos engineering and Chaos Studio can help you in enhancing and preserving your software resilience, in an effort to confidently launch to manufacturing.
Uncover the advantages of Chaos Studio
To start your journey on Chaos Studio, seek the advice of the documentation for a abstract of ideas and how-to guides. When you grasp the advantages of chaos testing and Chaos Studio, a vital subsequent step is to include this into your launch pipeline validation.